
주뇽's 저장소
성능테스트를 위한 JMeter 사용 방법(2) - Redis를 이용한 성능 개선 본문
2024.06.15 - [웹개발] - 성능테스트를 위한 JMeter 사용 방법(1)
성능테스트를 위한 JMeter 사용 방법(1)
2024.06.15 - [웹개발] - 성능테스트를 위한 윈도우와 Mac에서 JMeter 설치 방법 성능테스트를 위한 윈도우와 Mac에서 JMeter 설치 방법Apache JMeter는 성능 테스트 및 부하 테스트를 위한 도구로 널리 사용
jypark1111.tistory.com
이전 포스팅을 통해 JMeter를 통해 인기 게시글 100개를 조회를 할 때 성능테스트를 진행하였다. 이 때 100명의 유저가 초당 10명씩 GET 요청을 보내는 행위를 총 10번 진행해서 1000개의 Sample 데이터를 얻을 수 있었고, 그 결과는 상당히 좋지 못했다. 이러한 문제점을 해결하기 위해서는 여러가지 방법이 존재하지만 나는 크게 2가지를 생각하였다.
데이터베이스 최적화
인덱스 최적화
- 인덱스란?: 테이블 데이터를 빠르게 검색하기 위한 자료 구조.
- 최적화 방법: 자주 사용되는 컬럼에 인덱스 추가, 복합 인덱스 사용, 불필요한 인덱스 제거, 인덱스 크기 관리.
쿼리 최적화
- 쿼리 최적화란?: SQL 쿼리의 실행 성능을 향상시키기 위한 과정.
- 최적화 방법: 필요한 데이터만 조회, 서브쿼리 최소화, JOIN 순서 최적화, 인덱스 활용, 쿼리 실행 계획 분석, 캐싱 사용.
캐싱 전략
캐시 사용
- 캐시란?: 자주 접근하는 데이터를 메모리에 저장하여 접근 속도를 높이는 임시 저장소.
- 캐시 종류: 메모리 캐시, 분산 캐시 (Redis, Memcached), CDN 캐시.
캐시 전략
- 읽기 캐시: 자주 읽는 데이터를 캐시.
- 쓰기 캐시: 데이터를 캐시에 먼저 기록한 후 비동기적으로 데이터베이스에 기록.
- TTL 설정: 캐시 데이터의 유효 기간 설정.
- 캐시 무효화: 데이터 변경 시 캐시 갱신.
- 사이드카 패턴: 캐시 서버를 애플리케이션과 별도로 운영하여 확장성 높임.
캐시 갱신 정책
- 시간 기반 갱신 (TTL): 일정 시간이 지나면 캐시 갱신.
- 이벤트 기반 갱신: 데이터 변경 시 캐시 갱신.
- 쓰기 스루 (Write-Through): 데이터베이스와 캐시에 동시에 기록.
- 쓰기 비하인드 (Write-Behind): 먼저 캐시에 기록 후 비동기적으로 데이터베이스에 기록.
- 캐시 미스 (Cache Miss): 캐시에 데이터가 없을 경우 데이터베이스에서 조회 후 캐시에 저장.
Redis 선택 이유
성능
- 고속 데이터 접근: 메모리 기반으로 매우 빠른 읽기 및 쓰기 속도를 제공.
- 높은 처리량: 초당 수십만 개의 요청을 처리 가능.
기능성
- 다양한 데이터 구조 지원: 문자열, 해시, 리스트, 셋 등.
- TTL 설정: 각 키에 TTL을 설정하여 캐시 데이터의 유효 기간 관리.
- 퍼시스턴스: 메모리 기반이지만 디스크에 데이터 저장 옵션 제공.
확장성
- 수평적 확장: 클러스터링을 통해 확장 가능.
- 분산 처리: 여러 노드에 데이터 분산 저장.
커뮤니티 및 지원
- 풍부한 자료와 지원: 활발한 커뮤니티와 풍부한 자료, 상업적 지원 제공.
비용 효율성
- 인프라 비용 절감: 데이터베이스 부하 감소로 서버 스펙 낮출 수 있음.
- 오픈 소스: 라이선스 비용 없이 사용 가능, 클라우드 환경에서 쉽게 이용 가능.
이와 같은 이유들로 Redis를 선택하면 백엔드 시스템의 성능을 향상시키고, 응답 시간을 단축시키며, 더 나은 사용자 경험을 제공할 수 있다.
블로그 포스트: Redis를 사용한 Spring Boot 애플리케이션 성능 개선
웹 애플리케이션의 성능은 사용자 경험에 큰 영향을 미친다. 특히 많은 양의 데이터를 다루는 경우 성능 최적화는 필수적이다. 이번 포스트에서는 Spring Boot 애플리케이션에서 Redis의 Zset 자료구조와 캐싱을 활용하여 HTTP 요청의 응답 시간을 크게 개선하는 방법을 소개한다.
문제점
Jmeter를 통해 애플리케이션 성능 테스트를 진행해보니 초당 처리량과 응답 시간이 상당히 높은 것을 확인할 수 있었다. 기존 방식은 총 10000개의 게시글 중 좋아요 개수를 기준으로 상위 100개의 게시글을 반환하는 서비스 로직을 사용하고 있었으며, 이로 인해 다음과 같은 성능 문제가 발생했다.
성능 테스트 결과:
- 초당 요청 수: 0.578
- 평균 응답 시간(ms): 16296
기존 서비스 로직:
// 1. 모든 게시글 조회
List<Post> allPosts = postRepository.findAll();
// 2. 좋아요 개수를 기준으로 내림차순 정렬
allPosts.sort(Comparator.comparingInt((Post post) -> post.getLikes().size()).reversed());
// 3. 원하는 개수만큼 선택하여 반환
return allPosts.stream().map
(post -> PostResponse.from(post, userAccountRepository))
.limit(limit).collect(Collectors.toList());해결 방법
Redis의 Zset 자료구조와 캐싱을 사용하여 성능을 개선했다.
1. Redis 설정
프로젝트에 Redis 의존성을 추가하고 Redis 설정 클래스를 작성한다.
2. Zset 자료구조를 이용한 게시글 관리
Zset을 사용하여 상위 100개의 게시글을 빠르게 조회하도록 변경한다.
// 1. ZSet을 이용하여 100개의 인기 게시글 조회
ZSetOperations<String, Object> zSetOps = myredisTemplate.opsForZSet();
Set<ZSetOperations.TypedTuple<Object>> topPostIdsWithScores = zSetOps.reverseRangeWithScores(POPULAR_POSTS_KEY, 0, limit-1);
// 2. Long 타입으로 변환
Set<Long> topPostIds = Objects.requireNonNull(topPostIdsWithScores).stream()
.map(typedTuple -> Long.valueOf(typedTuple.getValue().toString()))
.collect(Collectors.toSet());
// 3. 100개의 PostId를 이용해서 DB에서 해당 게시글만 조회
List<Post> posts = postRepository.findAllById(topPostIds);
return posts.stream().map(post -> PostResponse.from(post, userAccountRepository)).collect(Collectors.toList());3. 캐싱 적용
캐싱을 통해 Redis에서 게시글 데이터를 빠르게 조회하도록 한다.
// 1. ZSet을 이용해 게시글 ID 100개 가져오기
Set<Long> topPostIds = getTopPostIds(limit);
// 2. Redis 해시에서 게시글 데이터 조회
List<PostResponse> posts = topPostIds.stream()
.map(postId -> postRedisTemplateService.getPostFromCache(postId.toString()))
.filter(Objects::nonNull)
.collect(Collectors.toList());
// 3. Redis에 없는 데이터는 MySQL에서 조회 후 Redis에 캐시
if (posts.size() < topPostIds.size()) {
Set<Long> cachedPostIds = posts.stream().map(PostResponse::id).collect(Collectors.toSet());
Set<Long> missingPostIds = topPostIds.stream()
.filter(postId -> !cachedPostIds.contains(postId))
.collect(Collectors.toSet());
List<PostResponse> missingPosts = postRepository.findAllById(missingPostIds).stream().map(post -> PostResponse.from(post, userAccountRepository)).toList();
posts.addAll(missingPosts);
// 조회한 Post를 Redis 해시에 캐시
missingPosts.forEach(postRedisTemplateService::save);
}
return posts;성능 개선 결과
위의 방법을 통해 성능이 크게 개선되었다.
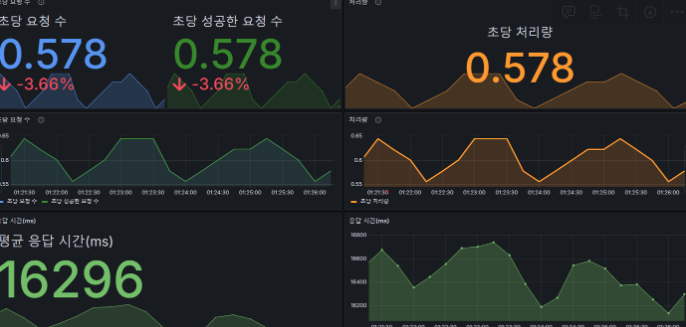
개선전 성능 테스트 결과:
- 초당 요청 수: 0.578
- 평균 응답 시간(ms): 16296
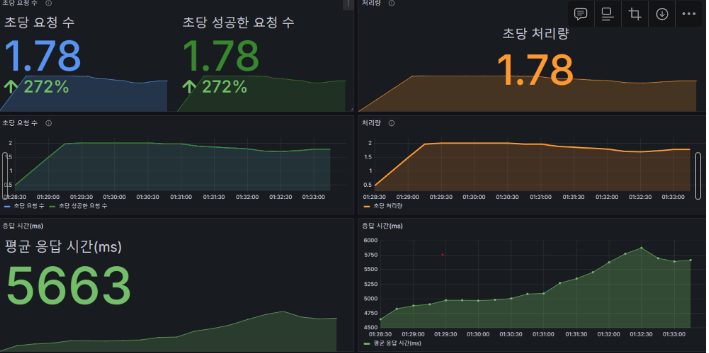
개선된 성능 테스트 결과:
- 초당 요청 수: 1.78 (272% 증가)
- 평균 응답 시간(ms): 5663 (65% 감소)
Redis 해시를 사용하여 추가로 성능을 최적화하였으며, 결과는 더욱 향상되었다.
최종 성능 테스트 결과:
- 초당 요청 수: 207 (상승)
- 평균 응답 시간(ms): 483 (97% 감소)

Redis와 캐싱을 활용한 성능 최적화는 데이터베이스 부하를 줄이고 빠른 응답 시간을 제공하는 데 매우 효과적이다. 이를 통해 웹 애플리케이션의 성능을 크게 향상시킬 수 있으며, 사용자 경험도 개선할 수 있다.
'웹개발' 카테고리의 다른 글
| 성능테스트를 위한 JMeter 사용 방법(1-2) 시각화 (2) | 2024.06.15 |
|---|---|
| 성능테스트를 위한 JMeter 사용 방법(1-1) (2) | 2024.06.15 |
| 성능테스트를 위한 윈도우와 Mac에서 JMeter 설치 방법 (0) | 2024.06.15 |



