
주뇽's 저장소
Transformer 본문
2023.08.08 - [DeepLearning/Paper Riview] - Attention Is All You Need
Attention Is All You Need
Attention Attention Is All You Need Transformer : Attention Is All You Need RNN (Recurrent Neural Network): RNN은 순차적인 데이터를 처리하는 데 사용되는 신경망 구조이다. RNN은 이전 시간 단계의 입력을 현재 시간 단계
jypark1111.tistory.com
Transformer는 자연어 처리(Natural Language Processing) 분야에서 주로 사용되는 모델 구조이다. Attention 메커니즘을 사용하여 입력 시퀀스를 처리하고, 병렬적인 계산을 통해 장기 의존성 문제를 해결한다. Transformer는 인코더와 디코더라는 두 개의 주요 구성 요소로 구성되며, 기계 번역, 챗봇 등 다양한 자연어 처리 작업에 적용된다.
- 특징: Self-Attention 메커니즘, 인코더-디코더 구조
- 장점: 병렬 계산에 용이하여 처리 속도가 빠름, 장기 의존성 문제를 해결, 자연어 처리에 적합
- 단점: 많은 메모리 요구, 학습 데이터 양의 증가에 민감
Transformer을 이용하여 IMDB 영화 리뷰 감성 분석
import numpy as np
import tensorflow as tf
import matplotlib.pyplot as plt
from tensorflow.keras.datasets import imdb(X_train, y_train), (X_test, y_test) = imdb.load_data()
print('훈련용 리뷰 개수 : {}'.format(len(X_train)))
print('테스트용 리뷰 개수 : {}'.format(len(X_test)))
num_classes = len(set(y_train))
print('카테고리 : {}'.format(num_classes))Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/imdb.npz
17464789/17464789 [==============================] - 1s 0us/step
훈련용 리뷰 개수 : 25000
테스트용 리뷰 개수 : 25000
카테고리 : 2
word_to_index = imdb.get_word_index()
index_to_word = {}
for key, value in word_to_index.items():
index_to_word[value+3] = keyDownloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/imdb_word_index.json
1641221/1641221 [==============================] - 0s 0us/step
for index, token in enumerate(("<pad>", "<sos>", "<unk>")):
index_to_word[index] = token
print(' '.join([index_to_word[index] for index in X_train[0]]))import re #-- 정규표현식을 사용하기 위한 모듈 임포트
from tensorflow.keras.datasets import imdb #-- IMDB 데이터셋을 로드하기 위한 모듈 임포트
from tensorflow.keras.preprocessing.sequence import pad_sequences #-- 시퀀스 패딩을 위한 모듈 임포트
from tensorflow.keras.models import Sequential #-- Sequential 모델을 사용하기 위한 모듈 임포트
from tensorflow.keras.layers import Dense, Embedding, SimpleRNN, LSTM #-- 다양한 레이어를 사용하기 위한 모듈 임포트
from tensorflow.keras.callbacks import EarlyStopping, ModelCheckpoint #-- 훈련 중단 및 모델 체크포인트를 위한 모듈 임포트
from tensorflow.keras.models import load_model #-- 모델 로드를 위한 모듈 임포트
vocab_size = 10000 #-- 사용할 단어의 개수를 지정하는 변수
max_len = 500 #-- 문장의 최대 길이를 지정하는 변수
(X_train, y_train), (X_test, y_test) = imdb.load_data(num_words=vocab_size)
#-- IMDB 데이터셋을 로드하고, num_words를 통해 빈도 기준 상위 vocab_size 개의 단어만 사용하여 데이터를 로드
#-- 훈련 데이터와 테스트 데이터로 구분
X_train = pad_sequences(X_train, maxlen=max_len)
X_test = pad_sequences(X_test, maxlen=max_len)
#-- pad_sequences를 사용하여 시퀀스 데이터인 X_train과 X_test의 길이를 맞춤
#-- maxlen을 통해 문장의 최대 길이를 설정하고, 부족한 길이의 문장은 0으로 패딩모델정의
class MultiHeadAttention(tf.keras.layers.Layer):
def __init__(self, embedding_dim, num_heads=8):
super(MultiHeadAttention, self).__init__()
self.embedding_dim = embedding_dim # 임베딩 차원
self.num_heads = num_heads # 어텐션 헤드의 개수
assert embedding_dim % self.num_heads == 0 # 임베딩 차원이 어텐션 헤드의 개수로 나누어 떨어지는지 확인
self.projection_dim = embedding_dim // num_heads # 어텐션 헤드 당 차원 크기
self.query_dense = tf.keras.layers.Dense(embedding_dim) # 쿼리에 대한 밀집층
self.key_dense = tf.keras.layers.Dense(embedding_dim) # 키에 대한 밀집층
self.value_dense = tf.keras.layers.Dense(embedding_dim) # 값에 대한 밀집층
self.dense = tf.keras.layers.Dense(embedding_dim) # 최종 출력을 위한 밀집층
def scaled_dot_product_attention(self, query, key, value): # 스케일된 닷 프로덕트 어텐션 함수
matmul_qk = tf.matmul(query, key, transpose_b=True) # 쿼리와 키를 곱함
depth = tf.cast(tf.shape(key)[-1], tf.float32) # 스케일링 팩터
logits = matmul_qk / tf.math.sqrt(depth) # 스케일링
attention_weights = tf.nn.softmax(logits, axis=-1) # 소프트맥스를 적용해 어텐션 가중치를 계산
output = tf.matmul(attention_weights, value) # 가중치와 값을 곱해 출력을 계산
return output, attention_weights
def split_heads(self, x, batch_size): # 입력을 여러 헤드로 분할하는 함수
x = tf.reshape(x, (batch_size, -1, self.num_heads, self.projection_dim)) # 입력을 적절한 형상으로 재구성
return tf.transpose(x, perm=[0, 2, 1, 3]) # 결과를 반환하기 전에 차원을 바꿈
def call(self, inputs): # 레이어의 전방향 연산
batch_size = tf.shape(inputs)[0]
query = self.query_dense(inputs) # 쿼리에 대한 밀집층을 통과
key = self.key_dense(inputs) # 키에 대한 밀집층을 통과
value = self.value_dense(inputs) # 값에 대한 밀집층을 통과
query = self.split_heads(query, batch_size) # 쿼리를 여러 헤드로 분할
key = self.split_heads(key, batch_size) # 키를 여러 헤드로 분할
value = self.split_heads(value, batch_size) # 값을 여러 헤드로 분할
scaled_attention, _ = self.scaled_dot_product_attention(query, key, value) # 스케일된 닷 프로덕트 어텐션을 계산
scaled_attention = tf.transpose(scaled_attention, perm=[0, 2, 1, 3]) # 차원을 바꿈
concat_attention = tf.reshape(scaled_attention, (batch_size, -1, self.embedding_dim)) # 헤드를 다시 합침
outputs = self.dense(concat_attention) # 최종 출력을 위한 밀집층을 통과
return outputs # 최종 출력을 반환
"""
Transformer 모델의 핵심적인 부분인 Multi-Head Attention 메커니즘을 구현
주요 작업들은 Query, Key, Value라는 세 가지 정보를 처리하고, 이 정보들 사이의 관계를 통해 입력 정보를 재조합한다.
"""
class TransformerBlock(tf.keras.layers.Layer):
def __init__(self, embedding_dim, num_heads, dff, rate=0.1):
super(TransformerBlock, self).__init__()
self.att = MultiHeadAttention(embedding_dim, num_heads) # 멀티 헤드 어텐션 레이어 생성
self.ffn = tf.keras.Sequential( # 포지션 와이즈 피드 포워드 신경망 생성
[tf.keras.layers.Dense(dff, activation="relu"),
tf.keras.layers.Dense(embedding_dim),]
)
self.layernorm1 = tf.keras.layers.LayerNormalization(epsilon=1e-6) # 첫번째 Layer Normalization
self.layernorm2 = tf.keras.layers.LayerNormalization(epsilon=1e-6) # 두번째 Layer Normalization
self.dropout1 = tf.keras.layers.Dropout(rate) # 첫번째 Dropout layer
self.dropout2 = tf.keras.layers.Dropout(rate) # 두번째 Dropout layer
def call(self, inputs, training): # 레이어의 전방향 연산 정의
attn_output = self.att(inputs) # 멀티 헤드 어텐션 수행
attn_output = self.dropout1(attn_output, training=training) # 어텐션 결과에 Dropout 적용
out1 = self.layernorm1(inputs + attn_output) # Add & Norm 적용
ffn_output = self.ffn(out1) # 포지션 와이즈 피드 포워드 신경망 수행
ffn_output = self.dropout2(ffn_output, training=training) # 포지션 와이즈 피드 포워드 결과에 Dropout 적용
return self.layernorm2(out1 + ffn_output) # 최종 결과 Add & Norm 적용
"""
TransformerBlock은 MultiHeadAttention을 포함하는 층으로, Transformer의 기본 구성 단위이다. 이 클래스는
멀티헤드 어텐션, 그리고 포지션 와이즈 피드 포워드 네트워크 두 개의 서브층으로 구성되어 있는데,
각 서브층 뒤에는 드롭아웃, Layer Normalization, 그리고 Residual Connection이 있다.
"""
class TokenAndPositionEmbedding(tf.keras.layers.Layer):
def __init__(self, max_len, vocab_size, embedding_dim):
super(TokenAndPositionEmbedding, self).__init__()
self.token_emb = tf.keras.layers.Embedding(vocab_size, embedding_dim) # 토큰 임베딩 레이어 생성
self.pos_emb = tf.keras.layers.Embedding(max_len, embedding_dim) # 포지션 임베딩 레이어 생성
def call(self, x): # 레이어의 전방향 연산 정의
max_len = tf.shape(x)[-1]
positions = tf.range(start=0, limit=max_len, delta=1) # 포지션 값 생성
positions = self.pos_emb(positions) # 포지션에 대한 임베딩 결과 생성
x = self.token_emb(x) # 토큰에 대한 임베딩 결과 생성
return x + positions # 토큰 임베딩과 포지션 임베딩을 더하여 반환
"""
이 클래스는 각 토큰의 위치 정보를 포함하는 임베딩을 생성한다.
이는 Transformer가 입력 문장의 순서 정보를 놓치지 않도록 보장하고
이 클래스는 각 토큰과 그 위치에 대한 임베딩을 합산하여 반환한다.
"""
def selfAttention_model(): # SelfAttention Model 함수 정의
embedding_dim = 32 # 각 단어의 임베딩 벡터의 차원
num_heads = 2 # 어텐션 헤드의 수
dff = 32 # 포지션 와이즈 피드 포워드 신경망의 은닉층의 크기
inputs = tf.keras.layers.Input(shape=(max_len,)) # 입력 레이어 생성
embedding_layer = TokenAndPositionEmbedding(max_len, vocab_size, embedding_dim) # 임베딩 레이어 생성
x = embedding_layer(inputs) # 임베딩 레이어를 통과한 출력
transformer_block = TransformerBlock(embedding_dim, num_heads, dff) # 트랜스포머 블록 레이어 생성
x = transformer_block(x) # 트랜스포머 블록 레이어를 통과한 출력
x = tf.keras.layers.GlobalAveragePooling1D()(x) # 글로벌 평균 풀링 적용
x = tf.keras.layers.Dropout(0.1)(x) # Dropout 적용
x = tf.keras.layers.Dense(20, activation="relu")(x) # 완전연결층(Dense layer)를 통과한 출력
x = tf.keras.layers.Dropout(0.1)(x) # Dropout 적용
outputs = tf.keras.layers.Dense(2, activation="softmax")(x) # 최종 출력 레이어
es = EarlyStopping(monitor='val_loss', mode='min', verbose=1, patience=4) # 조기 종료 설정
model = tf.keras.Model(inputs=inputs, outputs=outputs) # 모델 생성
mc = ModelCheckpoint('sellAttention_model.h5', monitor='val_acc', mode='max', verbose=1, save_best_only=True) # 모델 체크포인트 설정
model.compile("adam", "sparse_categorical_crossentropy", metrics=["accuracy"]) # 모델 컴파일
history = model.fit(X_train, y_train, batch_size=32, epochs=20, callbacks=[es, mc], validation_data=(X_test, y_test)) # 모델 학습
return model # 학습된 모델 반환
"""
이 함수는 위에서 정의한 클래스들을 사용하여 최종 모델을 구성하고 학습하는 과정을 정의한다.
먼저 입력을 임베딩 층에 통과시키고, Transformer 블록에 통과시킨 후에 평균 풀링을 적용한다.
그 후에 두 개의 Dense 층을 거쳐 최종 출력을 만들어낸다.
"""import re
from tensorflow.keras.preprocessing.sequence import pad_sequences
word_to_index = tf.keras.datasets.imdb.get_word_index()
index_to_word = {}
for key, value in word_to_index.items():
index_to_word[value+3] = key
def sentiment_predict_att(new_sentence, loaded_model):
# 알파벳과 숫자를 제외하고 모두 제거 및 알파벳 소문자화
new_sentence = re.sub('[^0-9a-zA-Z ]', '', new_sentence).lower()
encoded = []
# 띄어쓰기 단위 토큰화 후 정수 인코딩
for word in new_sentence.split():
try :
# 단어 집합의 크기를 10,000으로 제한.
if word_to_index[word] <= 10000:
encoded.append(word_to_index[word]+3)
else:
# 10,000 이상의 숫자는 <unk> 토큰으로 변환.
encoded.append(2)
# 단어 집합에 없는 단어는 <unk> 토큰으로 변환.
except KeyError:
encoded.append(2)
pad_sequence = pad_sequences([encoded], maxlen=max_len)
# score = float(loaded_model.predict(pad_sequence)) # 예측
positive_score = float(loaded_model.predict(pad_sequence)[0][1])
nevative_score = float(loaded_model.predict(pad_sequence)[0][0])
print("{:.2f}% 확률로 긍정 리뷰입니다.".format(positive_score * 100))
print("{:.2f}% 확률로 부정 리뷰입니다.".format((nevative_score) * 100))모델 학습
embedding_dim = 100
hidden_units = 128
selfAtt = selfAttention_model()
from tensorflow.keras.utils import plot_model
plot_model(selfAtt, show_shapes=False, to_file='selfAtt_model.png')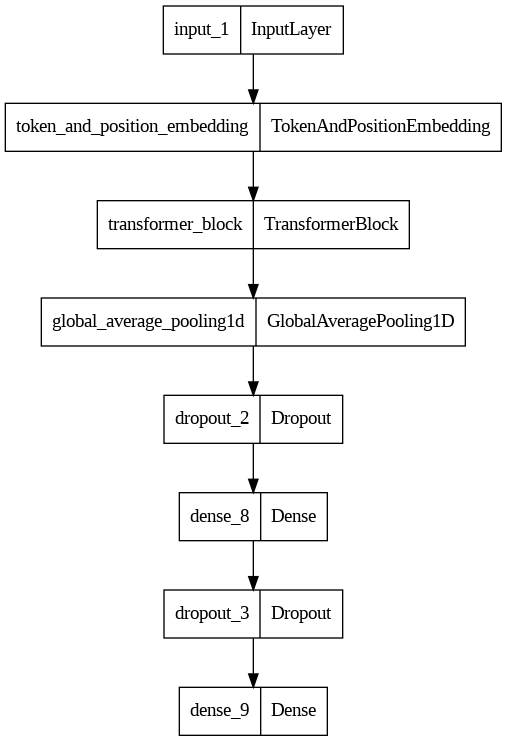
모델 평가
print("Self Attention 테스트 정확도: %.4f" % (selfAtt.evaluate(X_test, y_test)[1]))Self Attention 테스트 정확도: 0.8642
모델 예측
# 긍정적인 리뷰
positive_review = "I watched this film last night and it was an amazing experience. \
The performances by the actors were top notch and the storyline was gripping. \
The cinematography was beautiful, it really transported me into the movie's world. \
I highly recommend this film to anyone who enjoys quality cinema."
# 부정적인 리뷰
negative_review = "I really wanted to like this movie but it just didn't hit the mark for me. \
The plot was full of holes and the character development was almost non-existent. \
Despite having a strong cast, the performances were lackluster due to the weak script. \
I wouldn't recommend wasting your time on this one."
print("======================== 긍정적인 리뷰 =============================")
print("===========================트랜스포머 model 예측===========================")
sentiment_predict_att(positive_review, selfAtt)
print("======================== 부정적인 리뷰 =============================")
print("===========================트랜스포머 model 예측===========================")
sentiment_predict_att(negative_review, selfAtt)======================== 긍정적인 리뷰 =============================
===========================트랜스포머 model 예측===========================
1/1 [==============================] - 0s 33ms/step
1/1 [==============================] - 0s 38ms/step
99.60% 확률로 긍정 리뷰입니다.
0.40% 확률로 부정 리뷰입니다.
======================== 부정적인 리뷰 =============================
===========================트랜스포머 model 예측===========================
1/1 [==============================] - 0s 39ms/step
1/1 [==============================] - 0s 35ms/step
0.44% 확률로 긍정 리뷰입니다.
99.56% 확률로 부정 리뷰입니다.
'NLP > Transformer' 카테고리의 다른 글
| RNN, LSTM, Transformer IMDB 결과 분석 (0) | 2023.07.01 |
|---|
