
주뇽's 저장소
RNN (Recurrent Neural Network) 본문
2023.07.01 - [NLP/Transformer] - RNN, LSTM, Transformer IMDB 결과 분석
RNN, LSTM, Transformer IMDB 결과 분석
RNN, LSTM, SelfAttention을 원하는 문제에 활용하여 문제 해결하고 결과에 대한 고찰 및 분석하기. 목표 예제를 통해 NLP(RNN, LSTM, SelfAttention) 모델에 대해서 이해하기 RNN RNN은 순차적인 데이터를 처리하
jypark1111.tistory.com
RNN (Recurrent Neural Network):
RNN은 순차적인 데이터를 처리하는 데 사용되는 신경망 구조이다. RNN은 이전 시간 단계의 입력을 현재 시간 단계의 입력과 함께 처리하여 순차적인 정보를 유지하고 활용할 수 있고 텍스트, 음성 등 순차적인 시계열 데이터 처리에 유용하다
- 특징: 순차적인 데이터 처리, 이전 상태의 정보를 기억
- 장점: 순차적인 패턴을 학습할 수 있음, 시계열 데이터 처리에 적합
- 단점: 장기 의존성(Long-Term Dependency)을 잘 학습하지 못하는 문제, Gradient Vanishing/Exploding 등의 문제 발생
RNN을 이용하여 IMDB 영화 리뷰 감성 분석
import numpy as np
import tensorflow as tf
import matplotlib.pyplot as plt
from tensorflow.keras.datasets import imdb(X_train, y_train), (X_test, y_test) = imdb.load_data()
print('훈련용 리뷰 개수 : {}'.format(len(X_train)))
print('테스트용 리뷰 개수 : {}'.format(len(X_test)))
num_classes = len(set(y_train))
print('카테고리 : {}'.format(num_classes))Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/imdb.npz
17464789/17464789 [==============================] - 1s 0us/step
훈련용 리뷰 개수 : 25000
테스트용 리뷰 개수 : 25000
카테고리 : 2
word_to_index = imdb.get_word_index()
index_to_word = {}
for key, value in word_to_index.items():
index_to_word[value+3] = keyDownloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/imdb_word_index.json
1641221/1641221 [==============================] - 0s 0us/step
for index, token in enumerate(("<pad>", "<sos>", "<unk>")):
index_to_word[index] = token
print(' '.join([index_to_word[index] for index in X_train[0]]))import re #-- 정규표현식을 사용하기 위한 모듈 임포트
from tensorflow.keras.datasets import imdb #-- IMDB 데이터셋을 로드하기 위한 모듈 임포트
from tensorflow.keras.preprocessing.sequence import pad_sequences #-- 시퀀스 패딩을 위한 모듈 임포트
from tensorflow.keras.models import Sequential #-- Sequential 모델을 사용하기 위한 모듈 임포트
from tensorflow.keras.layers import Dense, Embedding, SimpleRNN, LSTM #-- 다양한 레이어를 사용하기 위한 모듈 임포트
from tensorflow.keras.callbacks import EarlyStopping, ModelCheckpoint #-- 훈련 중단 및 모델 체크포인트를 위한 모듈 임포트
from tensorflow.keras.models import load_model #-- 모델 로드를 위한 모듈 임포트
vocab_size = 10000 #-- 사용할 단어의 개수를 지정하는 변수
max_len = 500 #-- 문장의 최대 길이를 지정하는 변수
(X_train, y_train), (X_test, y_test) = imdb.load_data(num_words=vocab_size)
#-- IMDB 데이터셋을 로드하고, num_words를 통해 빈도 기준 상위 vocab_size 개의 단어만 사용하여 데이터를 로드
#-- 훈련 데이터와 테스트 데이터로 구분
X_train = pad_sequences(X_train, maxlen=max_len)
X_test = pad_sequences(X_test, maxlen=max_len)
#-- pad_sequences를 사용하여 시퀀스 데이터인 X_train과 X_test의 길이를 맞춤
#-- maxlen을 통해 문장의 최대 길이를 설정하고, 부족한 길이의 문장은 0으로 패딩모델정의
def rnn_model(): #-- RNN Model
model = Sequential() #-- Sequential 모델 생성
model.add(Embedding(vocab_size, embedding_dim)) #-- Embedding 레이어: 단어 임베딩을 학습하는 역할
model.add(SimpleRNN(hidden_units)) #-- SimpleRNN 레이어: RNN의 한 종류로, 시계열 데이터 처리에 사용됨
model.add(Dense(1, activation='sigmoid')) #-- Dense 레이어: 이진 분류를 위한 출력층
es = EarlyStopping(monitor='val_loss', mode='min', verbose=1, patience=4)
#---- 과적합을 방지하기 위한 EarlyStopping(조기 종료) 코드
mc = ModelCheckpoint('rnn_model.h5', monitor='val_acc', mode='max', verbose=1, save_best_only=True)
#-- 학습 모델을 저장하기 위한 checkpoint 저장
model.compile(optimizer='rmsprop', loss='binary_crossentropy', metrics=['acc'])
#-- 이진분류 문제이므로 binary_crossentropy를 사용하여 모델 컴파일
history = model.fit(X_train, y_train, epochs=15, callbacks=[es, mc], batch_size=64, validation_split=0.2)
#-- 모델 학습 history 저장
return modelimport re
from tensorflow.keras.preprocessing.sequence import pad_sequences
word_to_index = tf.keras.datasets.imdb.get_word_index()
index_to_word = {}
for key, value in word_to_index.items():
index_to_word[value+3] = key
def sentiment_predict(new_sentence, loaded_model):
# 알파벳과 숫자를 제외하고 모두 제거 및 알파벳 소문자화
new_sentence = re.sub('[^0-9a-zA-Z ]', '', new_sentence).lower()
encoded = []
# 띄어쓰기 단위 토큰화 후 정수 인코딩
for word in new_sentence.split():
try :
# 단어 집합의 크기를 10,000으로 제한.
if word_to_index[word] <= 10000:
encoded.append(word_to_index[word]+3)
else:
# 10,000 이상의 숫자는 <unk> 토큰으로 변환.
encoded.append(2)
# 단어 집합에 없는 단어는 <unk> 토큰으로 변환.
except KeyError:
encoded.append(2)
pad_sequence = pad_sequences([encoded], maxlen=max_len)
score = float(loaded_model.predict(pad_sequence)) # 예측
if(score > 0.5):
print("{:.2f}% 확률로 긍정 리뷰입니다.".format(score * 100))
else:
print("{:.2f}% 확률로 부정 리뷰입니다.".format((1 - score) * 100)) 모델 학습
embedding_dim = 100
hidden_units = 128
rnn = rnn_model()
from tensorflow.keras.utils import plot_model
plot_model(rnn, show_shapes=False, to_file='rnn_model.png')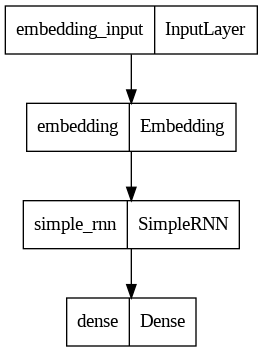
모델 평가
rnn_loaded_model = load_model('rnn_model.h5')
print("\n RNN Model 테스트 정확도: %.4f" % (rnn_loaded_model.evaluate(X_test, y_test)[1]))RNN Model 테스트 정확도: 0.8407
782/782 [==============================] - 8s 10ms/step - loss: 0.3047 - acc: 0.8764
모델 예측
# 긍정적인 리뷰
positive_review = "I watched this film last night and it was an amazing experience. \
The performances by the actors were top notch and the storyline was gripping. \
The cinematography was beautiful, it really transported me into the movie's world. \
I highly recommend this film to anyone who enjoys quality cinema."
# 부정적인 리뷰
negative_review = "I really wanted to like this movie but it just didn't hit the mark for me. \
The plot was full of holes and the character development was almost non-existent. \
Despite having a strong cast, the performances were lackluster due to the weak script. \
I wouldn't recommend wasting your time on this one."
print("======================== 긍정적인 리뷰 =============================")
print("===========================RNN model 예측===========================")
sentiment_predict(positive_review, rnn_loaded_model)
print("======================== 부정적인 리뷰 =============================")
print("===========================RNN model 예측===========================")
sentiment_predict(negative_review, rnn_loaded_model)======================== 긍정적인 리뷰 =============================
===========================RNN model 예측===========================
1/1 [==============================] - 0s 97ms/step
96.70% 확률로 긍정 리뷰입니다.
======================== 부정적인 리뷰 =============================
===========================RNN model 예측===========================
1/1 [==============================] - 0s 92ms/step
92.79% 확률로 부정 리뷰입니다.