
주뇽's 저장소
1-2 데이터 , 1-3 기계학습 본문
데이터에 대한 이해
과학 기술의 정립 과정
데이터 수집 → 모델 정립 → 예측
자연에서 발생한 데이터들을 통해 가설(모델)을 세우고 예측을 하는 것
기계학습
- 기계학습은 복잡한 문제/과업을 다룬다
- 지능적 범주의 행위들은 규칙의 다양한 변화 양성을 가짐
- 단순한 수학 공식으로 표현 불가능함
- 데이터를 설명할 수 있는 학습 모델을 찾아내는 과정이다.
# 알지 못하는 규칙을 데이터를 가지고 모델(가설)을 통해 찾는다.
데이터 생성 과정
데이터 생성 과정을 완전히 아는 인위적 상황의 예제(가상)
ex) 두 개 주사위를 던져 나온 눈의 합을 x라 할 때 , y = (x-7)^2 +1 점을 받는 게임
- 해당 상황은 데이터 생성 과정을 완전히 알고 있다
- x를 알면 정확히 y를 예측할 수 있다
위 예제는 기계학습에 범주에 들어가지않는다 기계학습은 수학적 설명이 불가능해야 한다.
위 처럼 수학적 설명이 가능한 예제들은 모델링을 통해 해결이 가능하다.
기계 학습 문제
- 데이터 생성 과정을 알 수 없음
- 단지 주어진 훈련집합 X,Y로 가설 모델을 통해 근사 추정만 가능
눈에 보이지 않지만 어떠한 규칙이 존재 (수학적 정의 불가) 훈련집합을 잘 학습시켜서 규칙을 설명
데이터의 중요성
- 데이터의 양과 질
- 주어진 과업에 적합한 다양한 데이터를 충분한 양만큼 수집 → 과업 성능 향상
ex) 정면 얼굴만 가진 데이터로 인식 학습을 하면 측면 얼굴은 매우 낮은 데이터 인식 성능을 가짐
- 주어진 과업에 적합한 다양한 데이터를 충분한 양만큼 수집 → 과업 성능 향상
#규칙을 모델(가설)을 통해 찾고싶다 → 데이터의 양과 질이 높을수록 규칙을 찾을 수 있다. (데이터 확보는 아주 중요)

#위 그래프를 보면 전통적인 머신러닝같은 경우 적은 데이터에서도 가장 좋은 효율을 보여준다 하지만 데이터가 늘어남에 따라 효율은 딱히 변화가 없다 그에 반해 딥러닝같은경우 적은 데이터를 가지고 학습할 경우 불필요한 값들이 많이 생겨 효율이 좋지 못하지만 데이터의 양이 늘어날 수록 효율이 많이 증가한다는 것을 볼 수 있다.
- 공개 데이터
- 기계 학습의 대표적인 3가지 데이터 : Iris ,MNIST, ImageNet
- UCI 저장소
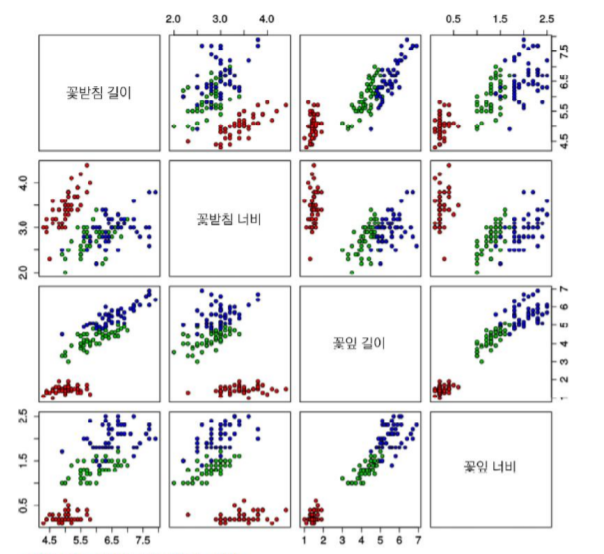
# Iris
Iris 데이터베이스는 통계학자인 피셔 교수가 1936년에 캐나다 동부 해안의 가스페 반도에 서식하는 3종의 붓꽃을 50송이씩 채취하여 만들었다. 150개 샘플 각각에 대해 길이, 꽃받침 너비, 꽃잎 길이, 꽃잎 너비를 측정하여 기록하였다. 따라서 4차원 특징 공간이 형성되며 목표값은 3종을 숫자로 표시함으로써 1,2,3값 중의 하나이다. http://archive.ics.uci.edu/ml/datasets/Iris 에 접속하여 내려받을 수 있다.

# MNIST
MNIST 데이터베이스는 미국표준국(NIST)에서 수집한 필기 숫자 데이터베이스로, 훈련집합 60,000자, 테스트집합 10,000자를 제공한다. http://yann.lecun.com/exdb/mnist/에 접속하면 무료로 받을 수 있으며, 1988년부터 시작한 인식률 경쟁 기록도 볼 수 있다.

# ImageNet
ImageNet 데이터베이스는 정보검색 분야에서 만든 WorldNet의 단어 계층 분류를 그대로 따랐고, 부류마다 수백에서 수천 개의 영상을 수집하였다. 총 21,841개 부류에 대해 총 14,197,122개의 영상을 보유하고 있다. 그중에서 1,000개 부류를 뽑아 ILSVRC라는 영상인식 경진대회를 2010년부터 매년 개최하고 있다. http://image-net.org 에서 내려받을 수 있다.

데이터의 중요성
데이터의 적은 양 → 차원의 저주와 관련
ex) MNIST : 28*28의 단순히 흑백으로 구성된다면 서로 다른 총 샘플 수는 2^784가지이지만, 샘플은 고작 6만 개 이다
6만개의 샘플은 784차원에서 본다면 아주 작은 데이터이다.
#차원의 저주 관점에서는 작은 데이터로 높은 차원의 규칙을 설명하기 힘들다 하지만 어떻게 MNIST는 높은 성능을 낼 수 있을까
- 적은 양의 데이터베이스로 어떻게 높은 성능을 달성하는가
- 방대한 공간에서 실제 데이터가 발생하는 곳은 매우 작은 부분 공간이다.
- 데이터 희소 특성을 가진다. (규칙에 의해 희소한 영역에서만 발생)
- 매니폴드(많이+끼다) 가정
- 고차원의 데이터는 관련된 낮은 차원의 매니폴드에 가깝게 집중되어 있다
→ 고차원의 규칙은 낮은차원에서도 보존
- 고차원의 데이터는 관련된 낮은 차원의 매니폴드에 가깝게 집중되어 있다
#MNIST같은 경우 실제로 데이터가 발생하는 부분이 매우작기때문에 작은 양으로도 높은성능이 가능하다
또한 숫자 2같은 경우 1차원으로 본다면 그려지는 과정이 → ← → 로 동일한 규칙을 가지고 있다. (매니폴드)
데이터 가시화
- 4차원 이상의 초공간은 한꺼번에 가시화가 불가능
- 여러 가지 가시화 기법
- 2개씩 조합하여 여러 개의 그래프 그림
#고차원의 특징은 저차원에서도 보존되어야 한다.
- 2개씩 조합하여 여러 개의 그래프 그림
1.3 간단한 기계 학습의 예
선형 회귀 문제
#선형 = 직선
문제
- 회귀 : 연속적 (예측 값)
- 분류 : 종류(개/고양이)
- 직선 모델(가설)을 사용하므로 두 개의 매개변수 = w, b
y = wx + b
목적 함수(비용 함수)
- 주어진 과업을 경험(data)를 통해 성능을 높이는 것을 추구 많이 맞으면 제대로 된 학습
- 선형 회귀를 위한 목적 함수
- 평균제곱오차(MSE)라 부름
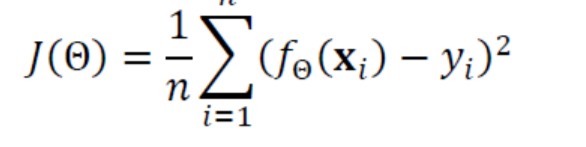
# 목적 함수가 좋을수록 성능은 올라간다.
- 𝑓Θ(𝐱𝑖 )는 예측함수의 예측 출력, yi는 예측함수가 맞추어야 하는 실제 목표치
- 𝑓Θ(𝐱𝑖 ) - yi는 오차error 혹은 손실loss
가설 - 실제 → 오차를 낮추기 위해 훈련을 실시 - 처음에는 최적 매개변수 값을 알 수 없으므로 임의의 난수로 로 Θ1 = (𝑤1, 𝑏1)ᵀ 설정
→ Θ2 =( 𝑤2, 𝑏2)ᵀ 로 개선 → Θ3 = (𝑤3, 𝑏3)ᵀ 로 개선 → Θ3는 최적해 - 이때 𝐽 (Θ1) > 𝐽 (Θ2) > 𝐽 (Θ3)
#에러를 낮출수록 성능은 올라간다.
선형 회귀 문제와 매개변수 최적화 관계의 예

최적화 이론을 통해 w1의 최솟값을 찾는 것
- Convex(최소의 해 1개)
- Non Convex(경사 하강법)
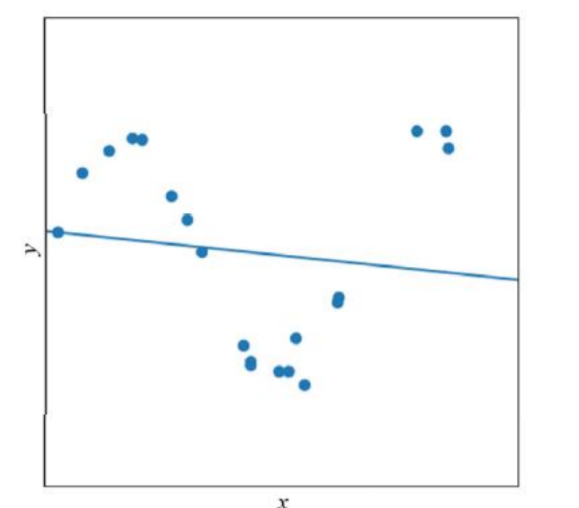
좀 더 현실적인 상황
- 지금까지는 데이터가 선형을 이루는 아주 단순한 상황만을 고려
- 실제 세계는 선형이 아니며 잡음이 섞임 → 비선형 모델이 필요 (신경망 또는 다차원)
'DeepLearning' 카테고리의 다른 글
| NVIDIA 딥러닝 기초 0. Tensorflow (0) | 2023.07.01 |
|---|---|
| 1-4 간단한 기계 학습의 예 (0) | 2021.10.28 |
| 1. 인공지능 소개 (0) | 2021.10.27 |

